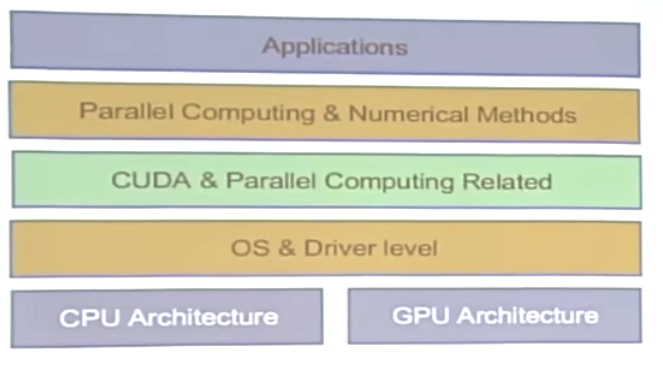
CUDA
CUDA
How to Learn CUDA
- Base Knowledge
GPU architecture understanding
Understand how GPUs work, especially when compared to CPUs.
The concept of parallel computing:
Understanding the basics of parallel processing and concurrent programming.
- relevant tools
NVIDIA’s 'GPU
CUDA Toolkit
Online Platform to learn CUDA
Google Colab
Kaggle Kernels
Microsoft Azure
Amazon AWS
-
C/C++ basic gramma
-
Introduction Project
-
Communities and forums
What is cuda?
2024/12/25 back to learn how to use cuda
CUDA: Compute Unified Devices Architecture
统一计算架构
cuda历史
计算机的图形处理 主要 依赖于 CPU
640x480的分辨率,每一帧的图片,需要30w个像素需要计算
internel 368/486 运行频率 在 16Mhz到66Mhz之间
把完成任务 比作 配送快递
16Hz 步行
66Hz 自行车
3D加速卡 Vodoo 3DFX开发 雷神之锤
1999 GPU GeForce256, 处理能力和灵活性大大提升
Shader 着色器: 可以灵活控制 3D model 顶点的位置 颜色等属性
图形处理的核心组件
2002 GPGPU
2006 GeFroce 8800 GTX, 支持通用计算的GPU, 引用的cuda 核心
cuda 核心 和 GPU核心的不同
CUDA 核心是 NVIDIA GPU 中的基础计算单元,专门用于处理并行任务。
GPU 核心指的是 GPU 的计算核心,是更大的逻辑单元,包括了多个 CUDA 核心和其他硬件模块。
一个计算的基本单元
一个是管理和调度多个cuda核心
- CUDA 核心 类似于工厂里的工人,每个工人负责完成一小部分具体的任务。
- GPU 核心 类似于工厂的生产线,每条生产线包含多个工人,还负责协调和管理工人分工。
SIMD
Single Instruction, Multiple Data
同时对多个数据执行相同指令的计算方式。
SI
指计算机指令的类型,比如加法、乘法、逻辑运算等。
在SIMD 模型中,所有计算单元执行的指令是相同的。
MD
指多个数据元素,这些数据通常是成组的,比如一组浮点数或一组整型数。
SIMD 的计算单元会同时对这组数据中的所有元素执行相同的运算。
eg
处理一个包含 1000 个数据的数组时,
SIMD 可以一次性对 4、8 或更多数据并行执行加法,而不是一个一个处理。
• 传统逐个处理(非SIMD):
假设你在邮寄信件,每次只能处理一封信(比如贴邮票)。
如果有100 封信,你需要重复这个动作100次。
• SIMD 并行处理:
假设你有一个机器可以一次性为4封信贴邮票。
这个机器(SIMD 模型)执行的指令是相同的(贴邮票),但它能同时处理多封信(多数据)。
Cuda 核心工具包 cuda tool kit
Tera Floating Point Operations Per Second
TFLOPS: 用来衡量GPU的浮点计算能力
each second 可以进行 多少万亿次的 浮点计算
浮点运算指的是加、减、乘、除等操作,通常用于处理小数和科学计算。
eg
假设 TFLOPS 表示一个工厂的生产能力:
- CUDA 核心数 是工厂中的工人数量。
- 时钟频率(GHz) 是工人的工作速度。
- 每周期浮点运算数 是工人在每一轮操作中完成的任务数量。
- 更高的 TFLOPS 表示工厂生产能力更强,但实际产量还受原材料(内存带宽)和管理效率(架构优化)的影响。
**Tensor核心: Volta 架构 **
专门为matrix 运算设计
专门为AI定制的
GPU 和 Cuda 的生态环境
多核系统 是 因为 单核系统遇到了瓶颈
CPU 架构
Pipelining
Branch Prediction: 怎么去预测下一个分支要执行什么
Superscalar
Out-of-Order (OoO) Execution Memory Hierarchy
Vector Operations
Multi-Core
什么是CPU?
完成基本的逻辑 和 算术指令 instruction
什么是指令
operation: add
get: access
control
对于Desktop Applcation来说,大部分时间是 在 搬运数据,很少是需要计算的。
Moore’s Law
芯片集成密度2年翻一倍,成本降一半。
一颗芯片图

8核
访存面积很大,主要是把data搬来搬去是占大头
Pipelining
CPU处理步骤
Fetch–> Decode–> Execute–> memory --> writeback
eg:
R1 = R2 + R3
- Fetch:从内存中取出 R1 = R2 + R3\text{R1 = R2 + R3}R1 = R2 + R3 这条指令。
- Decode:解码指令,理解需要从 R2 和 R3 取值,执行加法,并将结果存入 R1。
- Execute:将 R2 和 R3 的值通过 ALU 加法器相加。
- Memory:如果涉及内存读取或写入操作(此例中不需要)。
- Writeback:将计算结果写入寄存器 R1。
利用指令集 并行 instruction-level paralleism IIP
split the tasks into small basic steps and solve it
**Bypassing **
假设你有两个工人:
- 工人 A:负责从仓库取货。
- 工人 B:需要工人 A 的货物进行加工。
- 无 bypassing:
- 工人 A 必须先把货物送到存储区(Register),工人 B 才能取货加工。
- 如果存储区(Register)很远,工人 B 只能等,效率很低。
- 有 bypassing:
- 工人 A 直接把货物递给工人 B,跳过存储区(Register),节省时间。
- 工人 B 无需等待,可以立即开始加工。
Stalls
假设流水线是一个快递配送中心:
- 数据相关性:
- 第一位员工(指令 1)需要先完成包裹贴标签,第二位员工(指令 2)才能开始扫描包裹。
- 如果贴标签的工作没完成,扫描就得等待,这就造成了停滞。
- 控制相关性:
- 如果快递分拣线中有分岔点(条件跳转),系统需要知道包裹该往哪个方向送。
- 如果分岔方向不确定,所有工作就会停下来。
- 结构相关性:
- 如果分拣中心只有一条传送带,但同时有多个包裹需要运送,包裹就会堆积,造成停滞。
Branches
分支是实现循环、条件语句、函数调用的基础。
分支允许程序根据不同的条件执行不同的代码块,使程序更灵活。
假设你是一名司机,在一个十字路口前需要决定向左、向右还是直行:
- 条件分支
- 你观察红绿灯的状态(条件判断),根据灯的颜色决定是否直行或转弯。
- 无条件分支
- 你根据导航仪的指示,直接向某个方向前进,无需判断。
如果你提前预测方向(比如认为会是绿灯),但结果是错误的,就需要重新调整路径(类似于分支预测失败)。
Branch Prediction
你是一名送货员,来到一个十字路口,需要决定是否向左、向右或直行:
- 条件:如果客户下了订单,就往左送(左边是客户家)。
- 否则:如果订单未下,就直行回仓库。
但系统需要一定时间来确认客户是否下单。
- 没有分支预测:
- 你站在路口等待客户订单确认。
- 如果系统需要 5 秒确认,你的车停在路口 5 秒后,才能决定往哪个方向走。
- 问题:时间浪费,效率低。
- 有分支预测:
- 你根据历史经验(比如过去 90% 的客户都会下单),直接预测客户下了订单,于是你先往左行驶。
- 如果预测正确,你的选择是对的,时间没有浪费。
- 如果预测错误(客户没下单),你掉头返回仓库,这会造成时间浪费,但仍比完全等待更高效。
Another option: Predication
Predication 可以类比为在多人团队中并行处理多个任务:
- 传统分支(Branching):
- 如果某个任务需要判断条件(例如谁来完成任务 A 和任务 B),一个人等条件结果再行动,另一个人闲置。
- 如果判断条件错了,得重新安排任务。
- Predication:
- 两个人同时执行任务 A 和任务 B,但只有满足条件的任务结果被保留,另一个人的结果被丢弃。
- 虽然多消耗了一些资源,但避免了等待时间。
IPC:像是一个流水线生产线的效率指标,表示每秒能完成的产品数量。
Instructions Per Cycle: 完成一条instruction需要的clock sign frequency.
Superscalar:像是多个平行的生产线,它允许在同一时间处理多个产品,从而提高生产效率。
时钟周期 clock sign
一个clock sign就是 一个规律的 high low 电平交替
Sandy Bridge
- 取指(Fetch):
- 从指令缓存(L1 Cache)中提取多条指令。
- 解码(Decode):
- 每个时钟周期可以解码 4 条指令。
- 复杂指令被拆分为多个微操作。
- 调度(Schedule):
- 将微操作分配到合适的执行单元。
- 动态调度可以重排序指令,以减少数据相关性导致的停滞。
- 执行(Execute):
- 多个执行单元并行处理微操作,包括 ALU、FPU 和 SIMD 单元。
- 写回(Writeback):
- 执行结果写回到寄存器或内存。
单发射 vs 超标量:
- 单发射处理器:像一个单车道的道路,一次只能通过一辆车。
- 超标量处理器:像多车道高速公路,同一时间可以通过多辆车(多条指令)。
流水线与超标量结合:
- 流水线:不同阶段的工作并行执行。
- 超标量:每个阶段可以同时处理多条指令,就像每条车道上有多辆车。
动态调度器:
- 相当于交通信号灯,智能分配车流,避免拥堵。
Scheduling
将有限的资源高效分配给任务
Register Renaming
假设几名学生(指令)需要写作业,而每个人都有自己的作业纸(操作目标)。
学生们要使用一套有限的笔(Regiser)写作业。如果所有人都试图同时使用相同的笔,就会冲突。
为了解决这个问题,老师(Register Renaming硬件)给每位学生分配“编号”的笔(物理Register),而不是直接使用“共享的笔”(逻辑寄存器名)。这些编号对学生来说是透明的。
OoO
Out-of-Order Execution
假设一家餐厅有多张桌子,每张桌子点了多道菜,厨师需要尽快完成所有订单。
理想情况(顺序执行)
在顺序执行中,厨师会按照每桌点菜的顺序依次完成:
- 拿到第一个桌子的所有菜的订单。
- 开始逐道菜准备,直到第一个桌子的菜全部做好,再开始第二桌子的订单。
- 每张桌子的等待时间可能会很长,因为要等前面所有订单完成。
实际情况(乱序执行)
为了提高效率,餐厅会采用如下乱序策略:
- 厨师会查看所有订单,优先处理那些原料已经准备好、或者简单快做的菜。
- 如果某道菜的食材暂时不足(例如,需要等待肉解冻),厨师会暂时搁置这道菜,先去做其他可以立即准备的菜。
- 最终,所有桌子的菜都会端上去,但实际制作的顺序可能完全乱了。
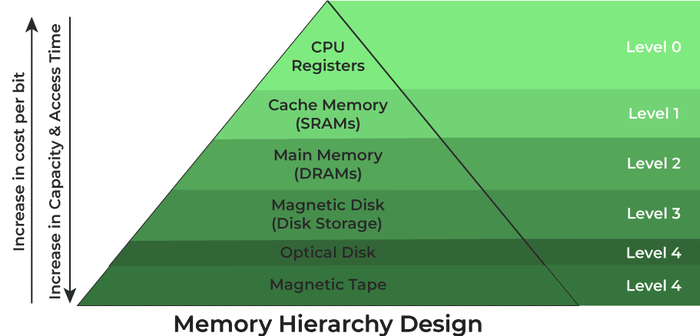
Memory Hierarchy
-
Register
-
Cache
将数据放在尽可能接近的位置
-
Main Memory/DRAM
-
Secondary Storage
-
Tertiary Storage
Memory Wall
散热原因导致 性能不能无限增加
Eg:
一辆车想要更快(更高时钟频率),需要更多的燃油(功耗)。
但车的油箱容量有限(散热能力有限),跑得太快会导致燃油消耗过快甚至损坏引擎(芯片过热)。
因此,汽车制造商不再单纯追求更高速度,而是选择更高效的引擎(多核处理)、更轻量化的设计(低功耗优化),以达到更高的整体性能。
从而导致 单核 走向 多核
还有 register wall等等
并行处理
并行计算是同时应用多个计算资源解决一个计算问题
Flynn matrix
SISD, SIMD, MISD, MIMD
一个工人在流水线上一次操作一个产品。
一群工人在流水线上做同样的工作,但处理不同的产品。
多个专家对同一份文档进行不同的分析。
多个工人在各自的流水线上独立完成不同的任务。
Observed Speedup
- 如果搬砖任务可以被完美拆分,且没有其他限制:
- 1 个人需要 100 分钟。
- 2 个人只需要 50 分钟,加速比是 2。
- 4 个人只需要 25 分钟,加速比是 4。
- 换句话说,人数越多,加速比线性增长。
这就是 理想加速比,即理论上随着处理器数量增加,性能成比例提升。
Parallel Overhead
执行并行程序时,额外增加的计算、时间或资源消耗,而这些消耗并不会直接用于完成实际的计算任务。
Task Partitioning Overhead
Task Scheduling Overhead
Communication Overhead
Synchronization Overhead
Resource Contention
Load Imbalance Overhead
任务分割开销:将一个大项目分解为多个小任务需要时间和精力
例如,为每个人分配工作、写清楚需求说明。
调度开销:项目经理需要分配任务、分配资源、跟进每个人的进度,这需要额外时间。
通信开销:团队成员之间需要开会讨论任务进展和问题(数据交换),这会占用工作时间。
同步开销:有些任务需要等待其他人完成,某人完成了部分设计后,另一个人才能开始编写代码。
资源竞争:如果团队只有一台打印机或有限的电脑,大家可能需要排队使用(资源争用)。
负载不均:如果某些人工作量较少,而其他人工作量繁重,就会导致效率下降。
并行编程模型
Shared Memory Model
共享存储模型就像一家共享厨房的餐厅,多个厨师在同一个厨房中做菜。如果他们使用相同的锅,需要协调避免互相干扰。
Threads Model
线程模型就像一个项目团队,每个成员(线程)有自己的工作任务,同时也可以协作完成共享任务。
Message Passing Model
消息传递模型就像一个远程协作团队,每个人独立工作,但通过电子邮件或聊天工具传递信息进行协作。
Data Parallel Model
数据并行模型就像一群人在不同的地块同时种植相同的作物,每个人负责自己的一块地。
| 模型 | 内存类型 | 通信方式 | 适用场景 |
|---|---|---|---|
| Shared Memory Model | 共享内存 | 通过共享变量 | 多线程、GPU并行 |
| Threads Model | 共享内存 | 通过本地或共享数据 | 多线程编程 |
| Message Passing Model | 独立内存 | 通过显式消息 | 分布式计算、网络通信 |
| Data Parallel Model | 通用 | 数据分片并分发 | 图形处理、大规模数据计算 |
syn
braodcast
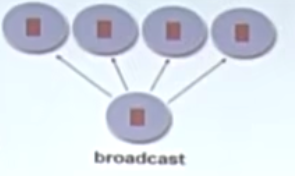
scatter
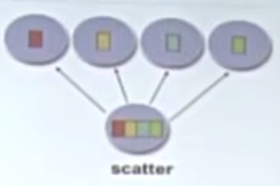
gather
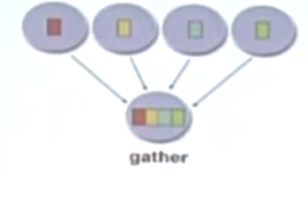
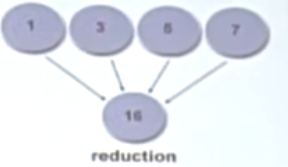
Reduction
Amdahl’s Law
程序可能的加速比取決于可以被并行化的部分。

假设你和朋友在搬家,任务分为两部分:
- 打包物品(只能一个人完成,串行部分)。
- 搬运物品(可以多人同时搬,完全并行化)。
- 如果打包物品占总时间的 20%,即使请更多的人帮忙搬运,打包部分始终限制了整体效率。
- 即使你有 100 个朋友,搬家的效率仍然不会超过打包的限制。
CUDA 环境搭建
下载 cuda toolkit
https://developer.nvidia.com/cuda-zone
本人是使用的mac系统,所以只能在线学习,下面是一个google 提供的平台学习cuda
https://github.com/depctg/udacity-cs344-colab
我是直接去google codelab创建一个notebook
然后runing time 切换为 GPU
输入
1 | !nvidia-smi |
1 | Thu Dec 26 14:44:54 2024 |
安装 cuda toolkit在google cloud
1 | !sudo apt update |
检查是否成功
1 | !nvcc --version |
hello word
1 | !sudo apt-get install g++ |
创建一个 hello.cu文件
1 |
|
1 | !nvcc hello.cu -o hello |
使用 NVIDIA CUDA 编译器 (
nvcc) 编译一个名为hello.cu的 CUDA 源文件,并生成一个名为hello的可执行文件。
nvcc:
- NVIDIA 的 CUDA 编译器,用于编译
.cu文件(CUDA C/C++ 源文件)。- 它会将代码中的主机代码(CPU 执行部分)交给主机编译器(如
g++),同时编译设备代码(GPU 执行部分)。hello.cu:
- 是您的 CUDA 源文件,包含 GPU 相关的代码。
-o hello:
- 指定输出的可执行文件名称为
hello
Kernel function
kernel fuc 在GPU上执行, cuda的核心部分。
通过 kernel 进行 parallel computing.(assign data into many thread on GPU)
在主机代码CPU中调用kernel func, 需要通过 cuda 配置 thread 和 block的数量。
使用方法:
kernel fuc 必须 使用`` global`修饰 —> 表示是 运行在 GPU上的function
return必须是 void
调用方式:
kernel fuc必须通过 <<<blocks, threads>>> 调用
1 | kernel_function<<<number_of_blocks, number_of_threads_per_block>>>(arguments); |
hello world from GPU
1 |
|
define kernel func:
- 使用
__global__修饰,声明一个运行在 GPU 上的函数- 返回值必须是
voidcall kernel func:
在主机代码(CPU)中通过
<<<blocks, threads>>>调用例如:
helloFromGPU<<<1, 1>>>();表示 GPU 上运行 1 个 block,每个 block 中 1 个threadGPU 是一个公司
- GPU 是一个处理大量计算任务的大型平台,就像一个公司,负责完成某些复杂的项目。
Block 是一个部门
- GPU 上的 block 就像公司中的一个部门。
- 每个部门可以独立完成分配给它的任务。
Thread 是一个员工
- 每个 block 内的 thread 就像部门中的员工。
- 每个员工负责一个具体的任务。
1 个 block, 1 个 thread 的情况
- 这就像整个公司中,只有一个部门,且这个部门只有一个员工。
- 这个员工需要完成部门的所有任务,因为没有其他人协助。
打印 “Hello, GPU!”。
- 任务分配:
- 只有一个部门(1 个 block),负责整个任务。
- 部门里只有 1 个员工(1 个 thread),这个员工会完成全部任务。
Synchronization:
使用
cudaDeviceSynchronize()确保 GPU 上的任务完成后再继续执行主机代码。线程同步 就像团队合作时,大家需要在某个阶段一起停下来,确认所有人完成了当前任务,再继续执行后续任务。
在google code中执行
1 | !nvcc hello_cuda.cu -o hello |
kernel function 不支持C++的istream
Cuda Thread Model
Compute Unified Device Architecture
NVDIA 提供GPU parallel computing framework
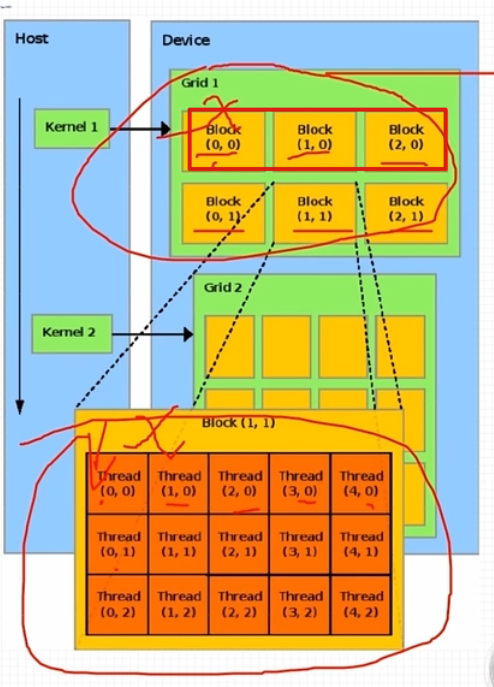
CUDA 线程模型是通过 Grid -> Block -> Thread 的分层结构实现的。
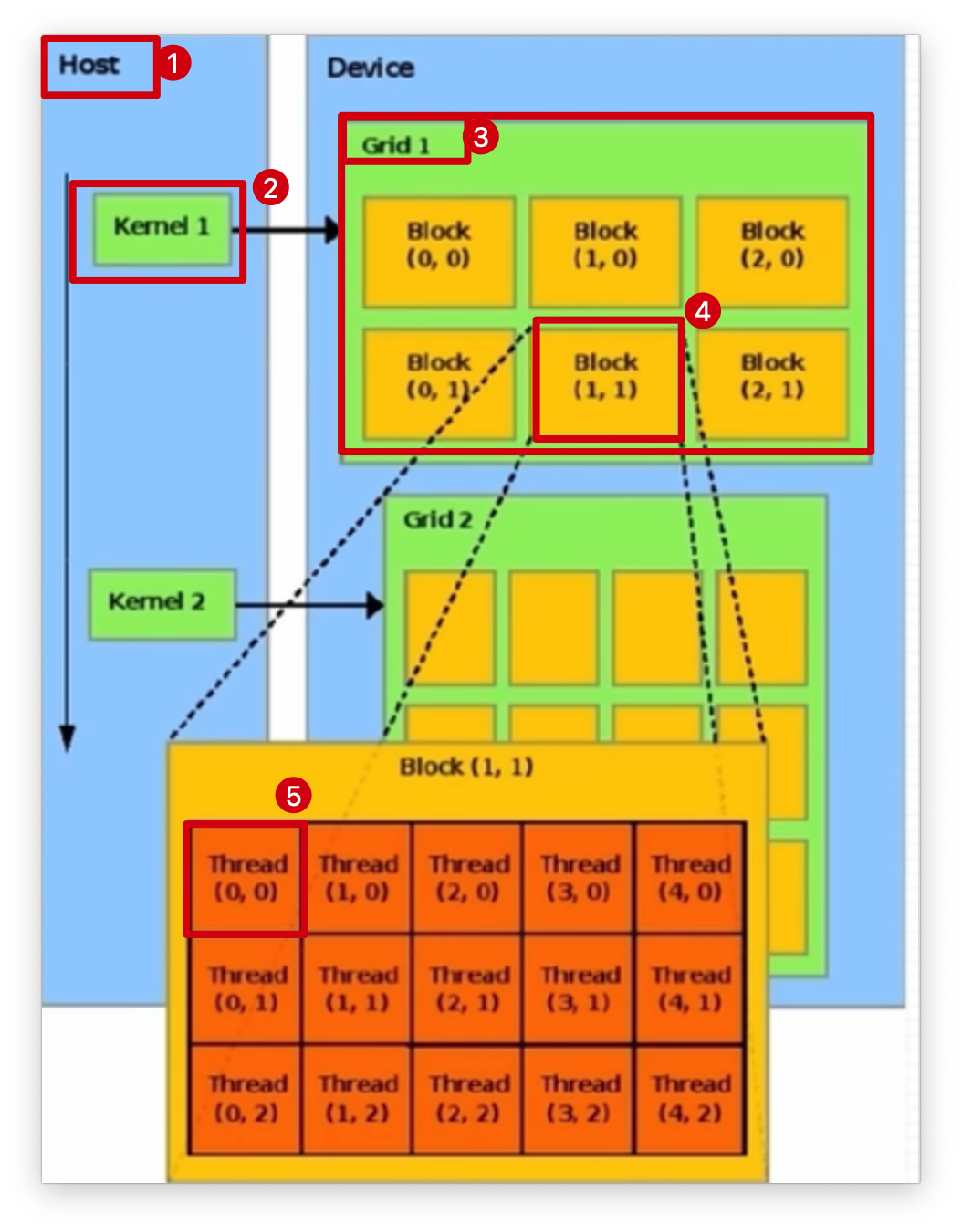
Grid 是最高层次的网格,包含多个 Block。
Block 是线程的集合,负责更小范围的任务。
Thread 是最小单位,执行具体计算。
Thread Model 层次
1. Grid(网格)
-
定义:由多个 Block 组成,是Thread的最高组织单位。
可以想象为城市, 每个城市(Grid)包含多个社区(Block)。
2. Block(线程块)
-
定义:由多个线程组成的计算单元。
可以想象为一个社区, 每个社区(Block)包含许多居民(Thread)。
3. Thread(线程)
-
定义:GPU 执行任务的最小单位。
可以想象为居民, 每个居民(Thread)负责具体的一小部分任务。
在cuda中,thread的层次结构用 三维坐标表示
1. Grid 的结构
- Grid 是 二维(x, y) 的网格。
- 每个 Grid 包含多个 Block。
2. Block 的结构
- Block 是 三维(x, y, z) 的线程块。
- 每个 Block 包含多个 Thread。
3. Thread 的唯一标识
每个线程在 Grid 中的唯一 ID 是由以下公式计算得到的:
1 | globalThreadID = blockIdx.x * blockDim.x + threadIdx.x; |
blockidx:Block 在 Grid 中的index。
blockDim:每个 Block 中Thread的数量。
threadIdx:Thread在 Block 中的index。
1 |
|
配置thread
<<<grid_size, block_size>>>
最大运行thread block 1024
在 CUDA 中,一个线程块(Block)最多可以包含 1024 个线程(Thread)。
blockDim.x * blockDim.y * blockDim.z ≤ 1024。线程块可以是 1D、2D 或 3D 结构,例如:
- 1D:
blockDim.x = 1024- 2D:
blockDim.x = 32, blockDim.y = 32(32×32 = 1024)- 3D:
blockDim.x = 8, blockDim.y = 8, blockDim.z = 16(8×8×16 = 1024)
最大运行block size 2^31 - 1 (1维网格)
网格(Grid)是由多个线程块(Block)组成的,最大支持 231−12^{31} - 1231−1 个线程块。
- 针对一维网格,这个值是 2,147,483,647。
- 针对二维网格,
gridDim.x和gridDim.y的最大值一般在 216−12^{16} - 1216−1 左右(具体限制根据硬件)。- 针对三维网格,
gridDim.z也有类似限制。
代码解释 <<<grid_size, block_size>>>
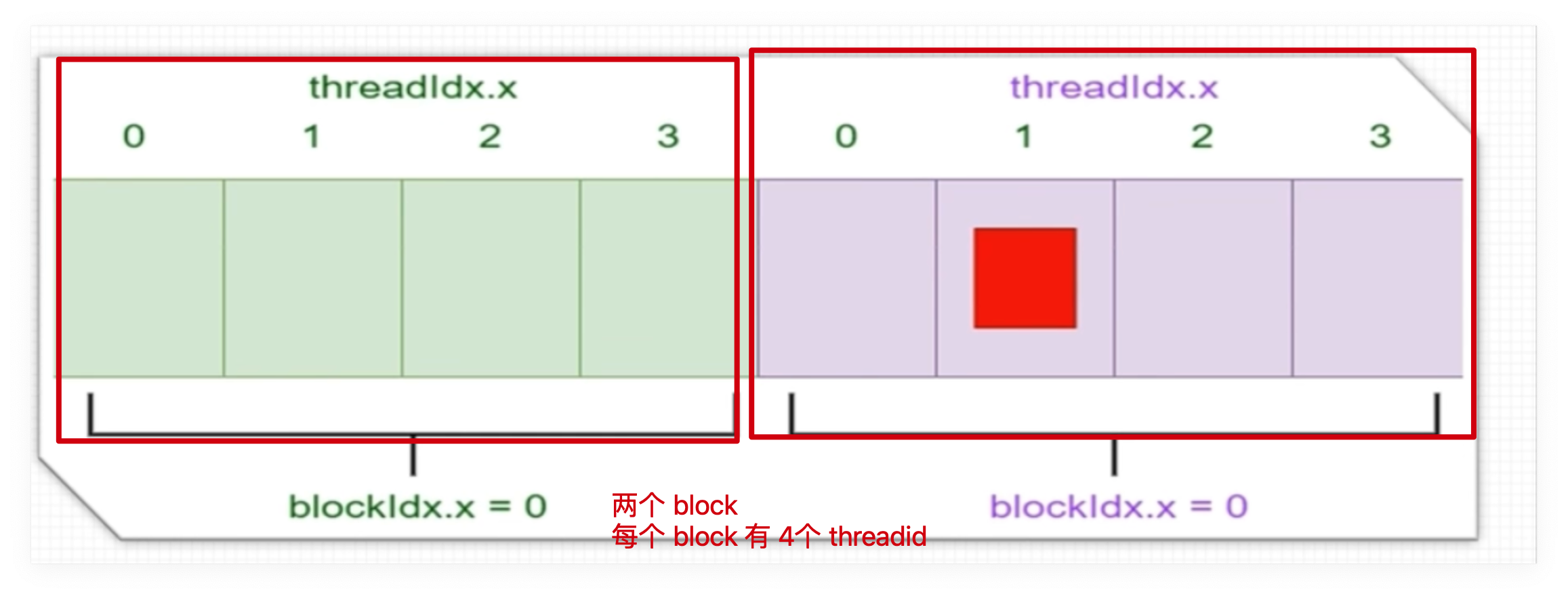
1 |
|
- gridDim.x = 2:网格有 2 个block.
- blockDim.x = 4:each block中有 4 thread.
计算过程
Block 0
threadIdx.x = 0,全局 ID =0 * 4 + 0 = 0threadIdx.x = 1,全局 ID =0 * 4 + 1 = 1threadIdx.x = 2,全局 ID =0 * 4 + 2 = 2threadIdx.x = 3,全局 ID =0 * 4 + 3 = 3Block 1
threadIdx.x = 0,全局 ID =1 * 4 + 0 = 4threadIdx.x = 1,全局 ID =1 * 4 + 1 = 5threadIdx.x = 2,全局 ID =1 * 4 + 2 = 6threadIdx.x = 3,全局 ID =1 * 4 + 3 = 7
多维thread
Cuda 可以是 3维的block 和 thread
网格可以在 x, y, z 三个维度上组织block
每个block也可以在 x, y, z 三个维度上组织thread
把 CUDA 的线程模型类比为一个高楼里的房间:
- 高楼(grid)
- 高楼由多层楼(线程块 block)组成
- 每一层楼都有一个唯一编号(通过
blockIdx.x, blockIdx.y, blockIdx.z表示)- 楼层( block)
- 每一层楼里有很多房间(线程 thread)
- 房间的位置通过
threadIdx.x, threadIdx.y, threadIdx.z表示
注意 坐标和矩阵是相反的
NVCC 编译流程和GPU计算能力
1.NVCC编译流程
NVCC是 NVIDIA 提供的 editor
负责将 CUDA source code 编译 为 execute program.
NVCC will split the code into 2 parts:
1.host code: run on CPU
2.deveice code: run on GPU
example to undestand NVCC
1 |
|
PTX
parallel Thread Execution
虚拟架构,用来describe GPU command
没有PTX,C/C++代码需要经过PTX转化为统一格式 (适用于不同的 GPU 架构)
CUBIN
CUDA binary
真正二进制代码,直接和GPU hard device对应
CUBIN是架构先关,必须为GPU的Compute Capability 编译。
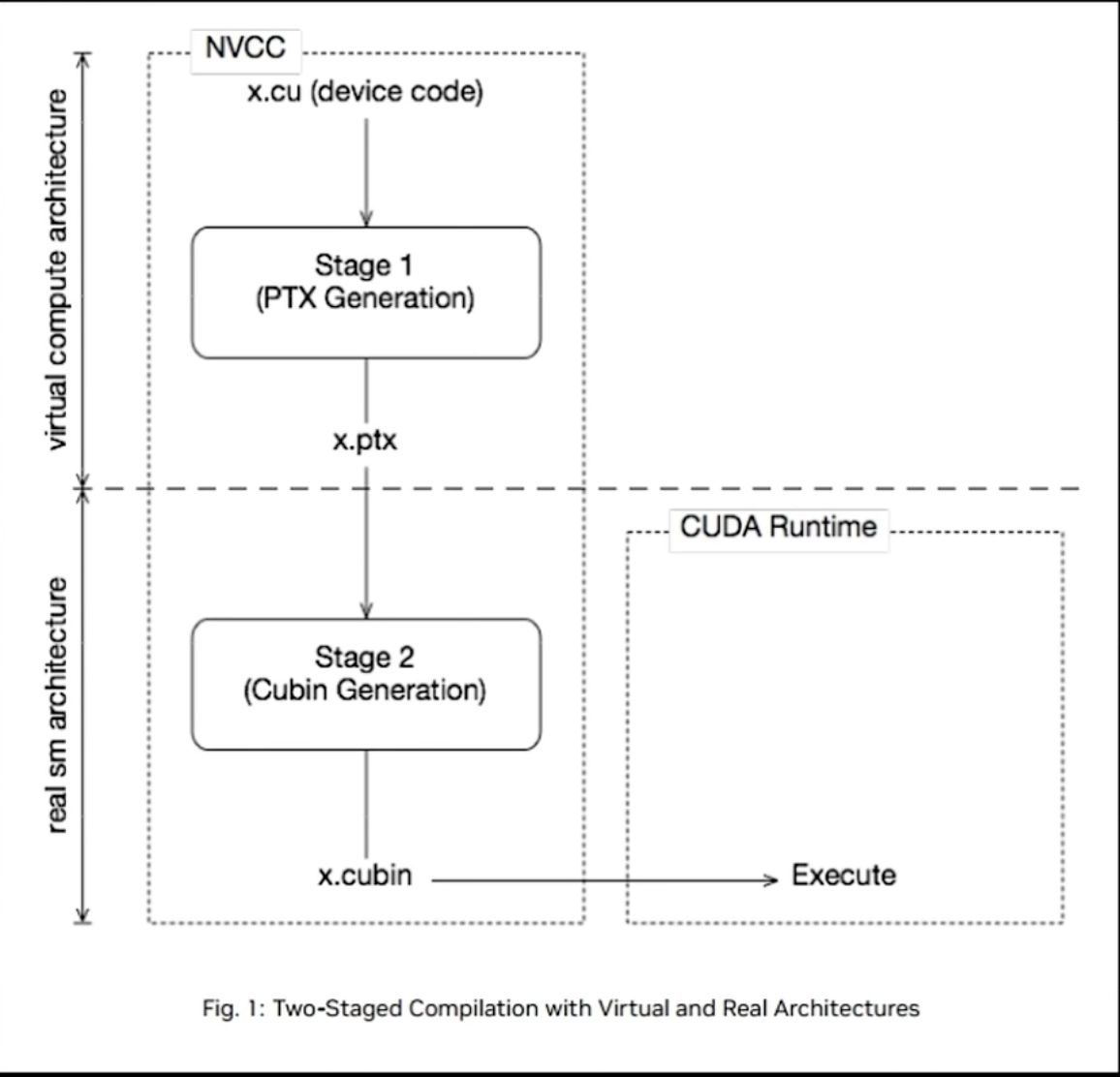
分为两个部分
1.virtual compute architecture
PTX 的generate
和 hardware无关
2.real sm architecture
将PTX转化为CUBIN
cuda运行时根据hardware生成
举个例子类比解释
将一本不知道什么语言书 翻译成 读者能看懂的书 让他阅读
- 原版数据 CUDA source code
- 通用英文版本 PTX
- 地方化版本 CUBIN
- 根据读者选择(CUDA runing)
你有一本书,需要让全世界不同地区的读者阅读。两个阶段
第一阶段:
把原始书(CUDA 源代码)翻译成一种通用的、易于理解的语言(比如标准化的英语)。
这个版本不包含地方特色,任何懂英语的人都能看懂
相当于 CUDA 编译器将设备代码生成 PTX 中间代码。
第二阶段:
根据地区,将通用版本 翻译为 符合当地习惯的版本(比如美国口音、英国口音或澳大利亚口音的英语)。
为美国读者提供“美国版技术书籍”,为英国读者提供“英国版技术书籍”。这就相当于 CUDA 的 PTX 被转译成适合具体 GPU 硬件(比如
sm_50、sm_70)的 CUBIN 二进制代码。运行阶段: 选择合适的版本
第一阶段 CUDA 生成 PTX
1 | nvcc -arch=compute_50 -ptx example.cu -o example.ptx |
输入 example.cud --> 包含host code 和 device code
输出 exmaple.ptx --> 生成的file
架构制定 -arch=compute_50: 生成支持计算能力 5.0 的 PTX 代码。
第二阶段 生成CUBIN
1 | nvcc -arch=compute_50 -code=sm_50 example.cu -o example.cubin |
将PTX 装华为 CUBIN
输入: example.cud --> 包含host code 和 device code
输出: example.cubion 是生成 计算能力 5.0 的目标架构(如 Tesla Maxwell 架构)可直接运行的二进制文件。
-code=sm_50 生成适用于计算能力 5.0 的 GPU 的二进制文件。
运行CUDA
-
CUDA 运行时加载 CUBIN 或 PTX
加载
1.1 有对应 GPU 架构的 CUBIN 文件,直接运行
1.2没有匹配的 CUBIN 文件,则运行时会动态编译 PTX 为目标硬件的二进制代码
-
运行
example.cubin 被加载并在目标GPU 上运行
CUDA Runtime 调用核函数(如 addKerne l<<<1,5>>>),完成计算任务
2.GPU计算能力
上次学习笔记到这为止
https://colab.research.google.com/drive/1xM2qO5ibOkshYU-LrGrYMdl7iGimzZq_#scrollTo=AdkPlBexiXu2
Reference
https://developer.nvidia.com/educators/existing-courses
https://zhuanlan.zhihu.com/p/56374118?utm_source=chatgpt.com