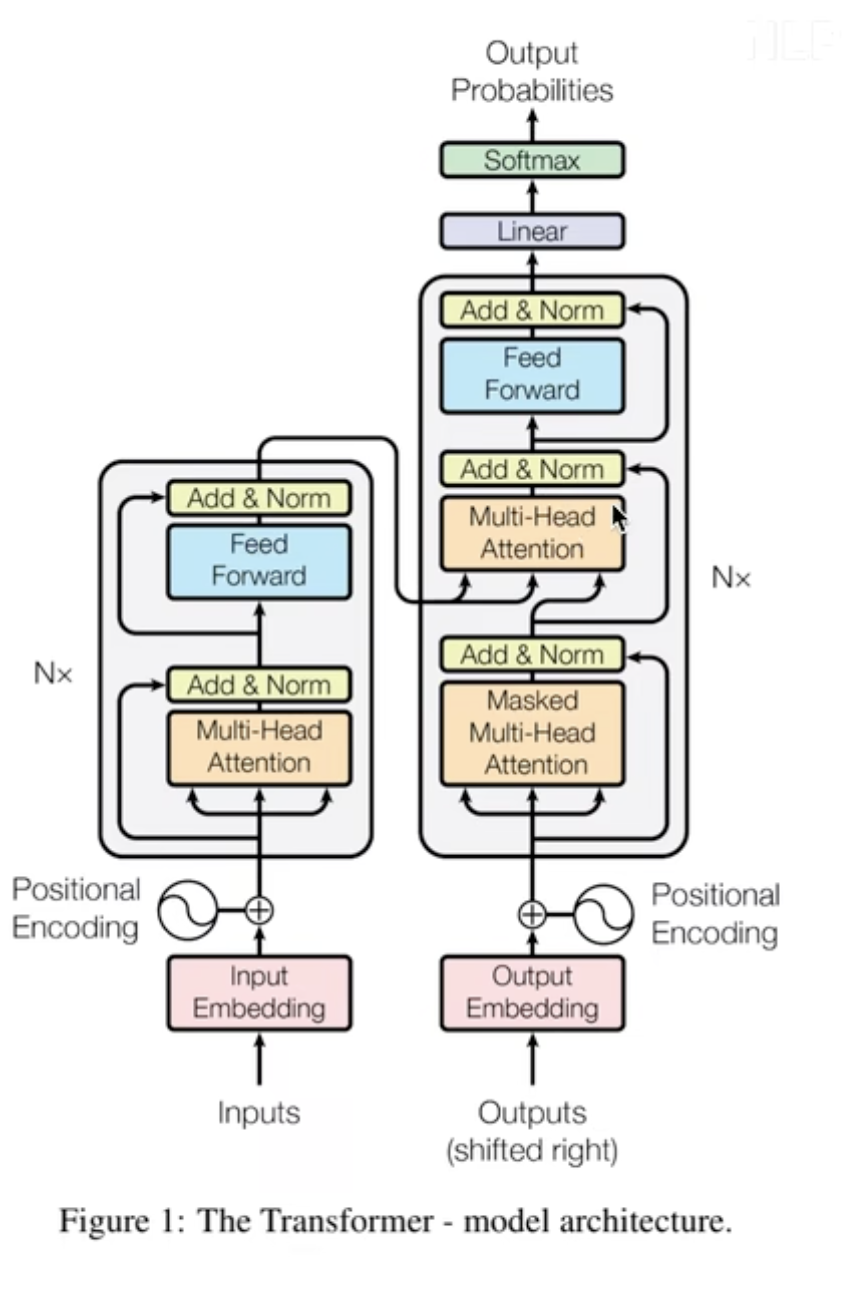
transformer
Transformer
This is my theoretical note about transformer.
The transformer is the stack of attention.
the details of encode sublayer
encode 和 decode 结构不同
decode 地方多了一个mask
上面的X n是负责 该code N份
The whole Frame of Transformer
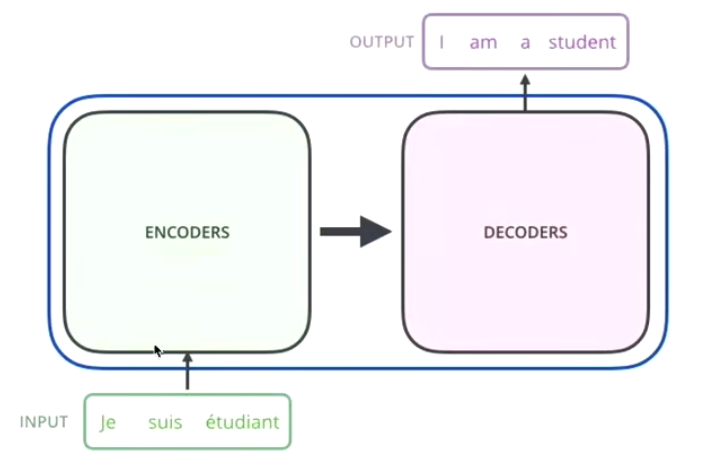
seq2seq: from encode to decode

using translation as the example to understand transformer
Input: Je suis étudiant
Middleware: transformer
Ountput: i am a student
the middleware include two parts: encodes and decodes
Encode: make the input into an word vector
Decode: generate the translation results, after getting the word vector from encode
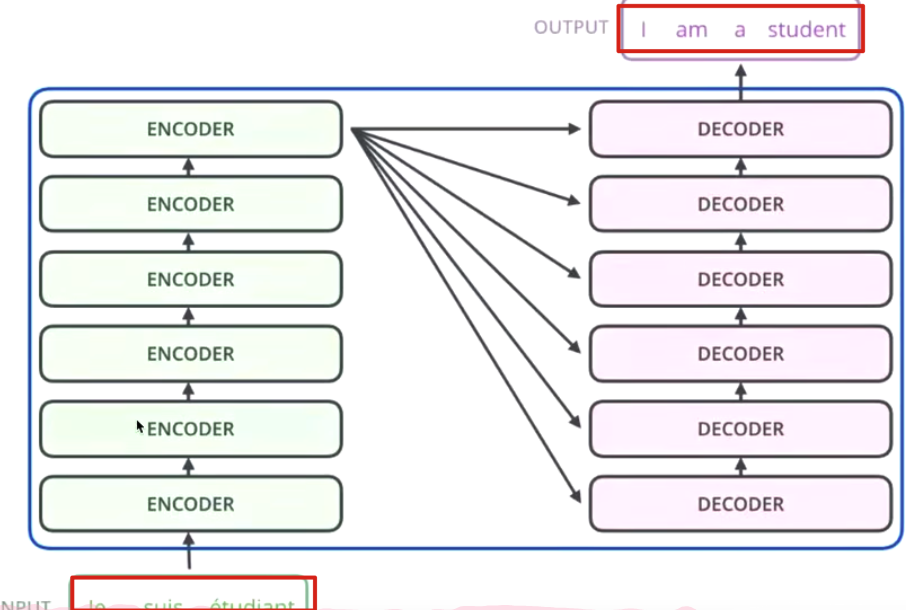
NX6 means: we gonna using 6 encde to strengthen our word vector
Encode and Decode
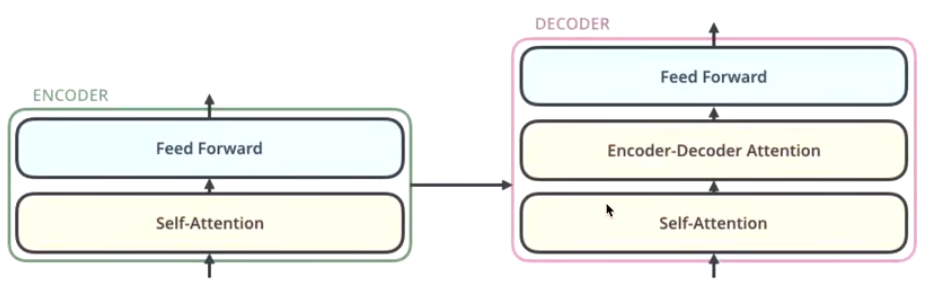
encode includes two sublayer: self-attention, feedforward
There will be one (residual network + normalization) during the transmission of each sublayer.
Encode
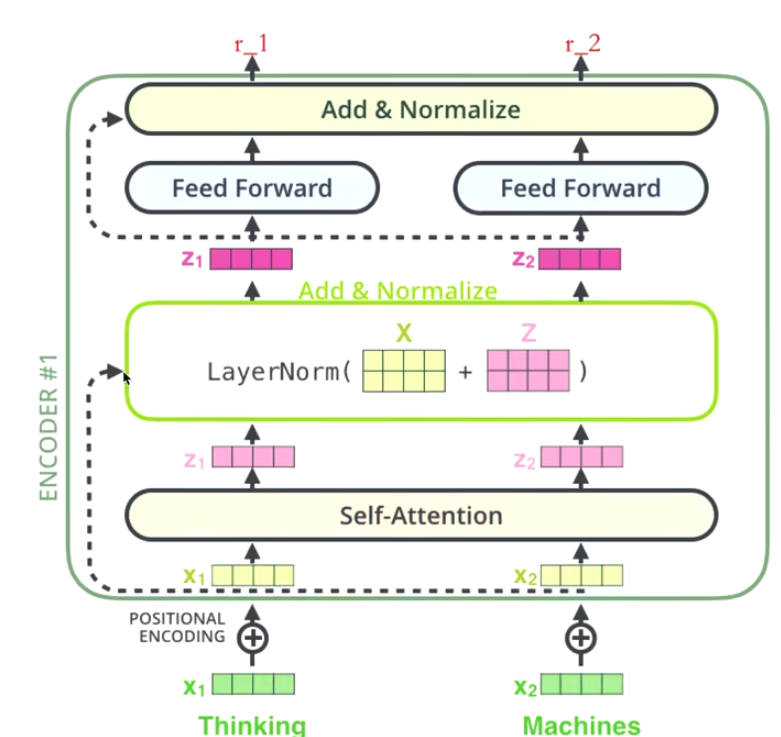
Eg:
Using a translation process as case to understand
- thinking —> get X1 (word Vector)(green color)
Can be acheived by one-hot, word2Vec
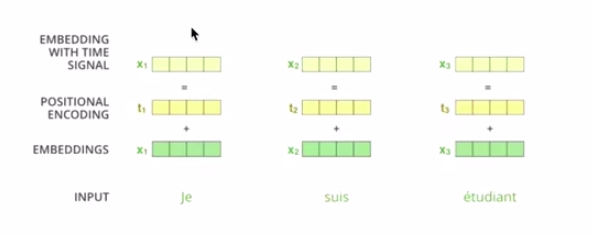
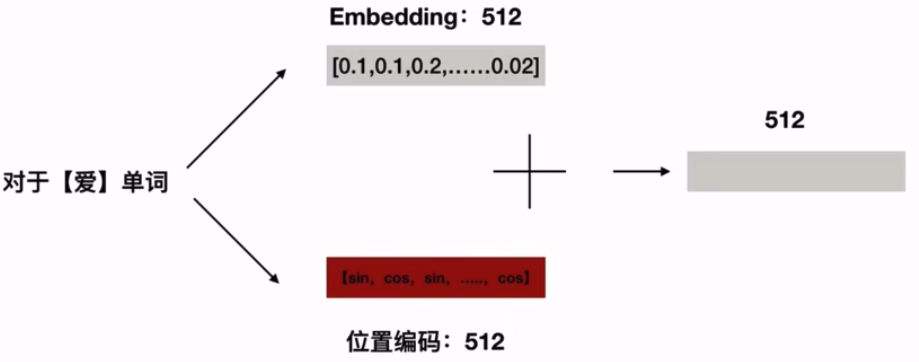
position coding —> get X1(yellow color)
Word vector superimposed position encoding
- Self attention —> get Z1 (pink color)
z1 has word vectors of positional features, syntactic features, and semantic features
- add residual network
residual network to avoid gradient disappears
W3(W2(W1 X +b1)+b2)+b3
If W1, W2, W3 is particularly small, like 0.0000000000000000.1,
X will disappear
W3(W2(W1 X +b1)+b2)+b3 + X
- layerNorm —> z1
normalization
avoid gradient explosion
- Feedforward —> r1
ReLu(W2(w1x + b1) + b2)
The previous step is doing linear transformation, wx+b,
the superposition of linear changes is always linear changes.
Make a nonlinear transformation through Relu in Feed Forward to get r1.
the linear change is the line translation or scale in the space.
the non-linear change make it can fit any state.
space translation and space distortion
summary
the key of encode is to make the word vector perfect.
the purpose of encode is to make the computer to understand the world.
Decode
The decoder will receive the word vector generated by the encoder, and then generate the translation result.
why we need mask self-attention?
Training phase:
je suis etudiant的翻译结果为I am a student,我们把
I am a student的Embedding 输入到 Decoders 里面,翻译第一个词。如果对
I am a studentattention 计算不做 mask,am, a,student对I的翻译将会有一定的贡献。如果对
I am a studentattention 计算做 mask,am,a,student对I的翻译将没有贡献。
Testing phase:
我们不知道
我爱中国的翻译结果为I love China我们只能随机初始化一个 Embedding 输入到 Decoders 里面,翻译第一个词
我无论是否做 mask,
Love,China对的翻译都不会产生贡献但是翻译了第一个词
I后,随机初始化的 Embedding 有了I的 Embedding,也就是说在翻译第二词
love的时候,I的 Embedding 将有一定的贡献,但是China对love的翻译毫无贡献,随之翻译的进行,已经翻译的结果将会对下一个要翻译的词都会有一定的贡献,这就和做了 mask 的训练阶段做到了一种匹配。
In summary:Decoder does Mask to make the behavior consistent between the training stage and the test stage, so that there is no gap and avoid overfitting.
encode: K and V
decode: Q
通过 new generated word as the key to do search in encode
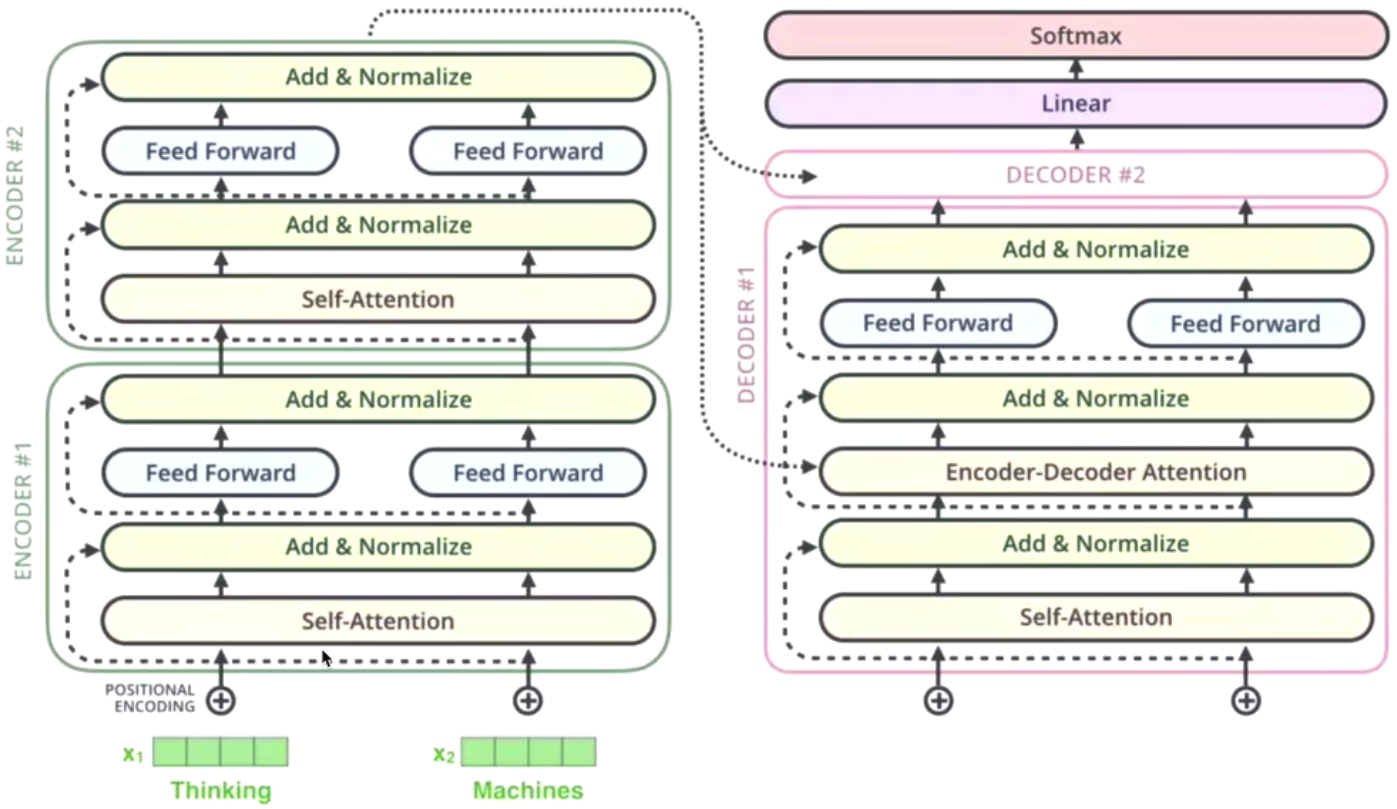
The input to the decoder is the new generated word
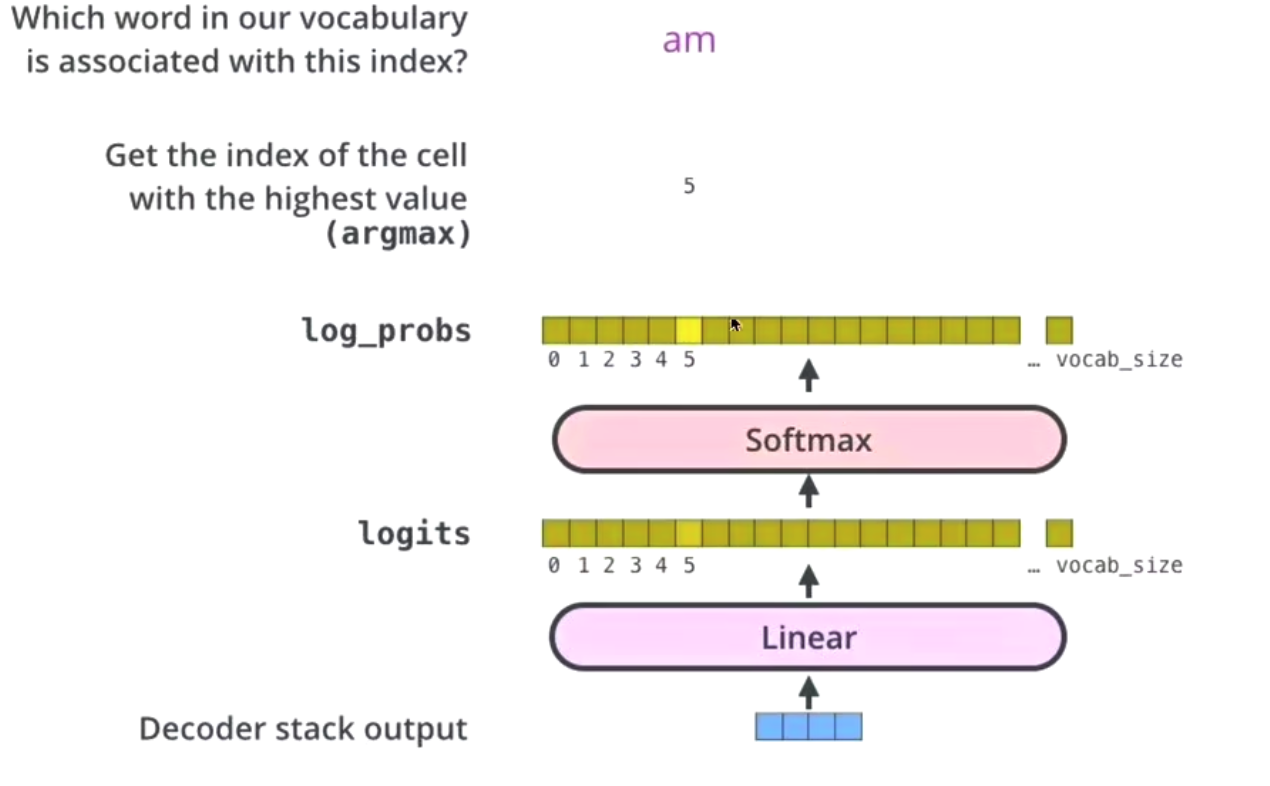
The linear layer is used to convert the output into the dimension of the vocabulary
Softmax gets the probability of the maximum word
The above figure dynamically shows how the transformer works
The different beteween encode and decode
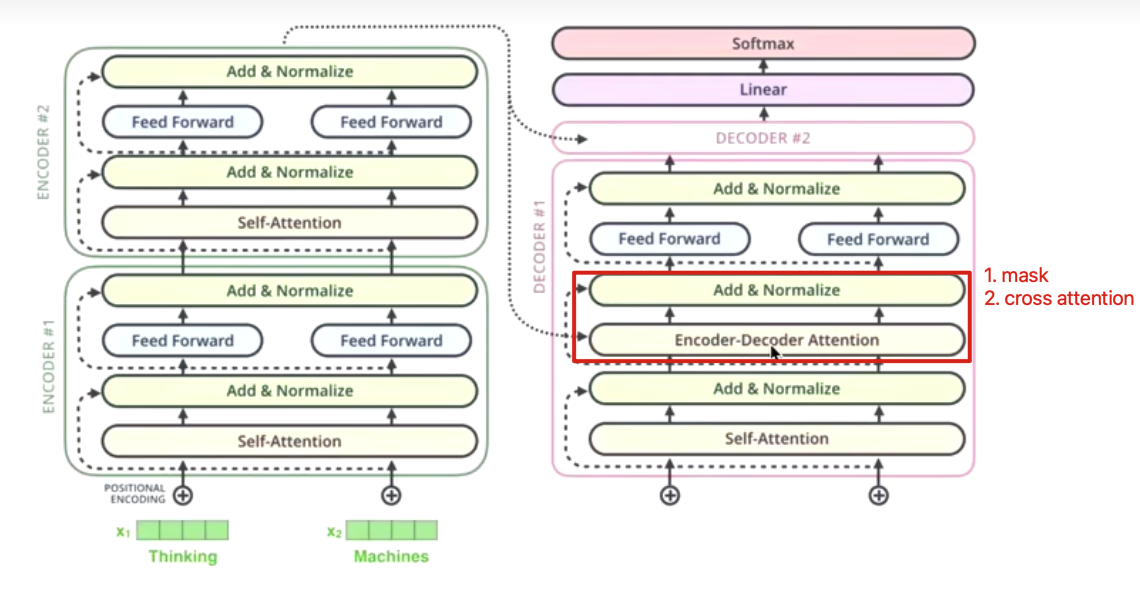
the decode using encoder-decoder attention
it’s function including two parts:
- do mask attention
- do cross attention
why need mask?
In order to solve the gap (mismatch) between the training stage and the test stage.
why encoders give K and V to decoders?
Q comes from decoder
K = V comes from encoder
K = V are source statement
When we generate this word, we pay attention to the new generated words
and the source statement to determine
which words in the source statement are more effective for the new generated following words.
以前seq2seq框架是 用 LSTM as encoder and decoder.
the essence of Deep Learning is:
The essence of AI model is to find a state in space to find the relationship of items in the real world.
1 | bert 就是把 decode 砍掉, 将encode 从6个增加到12个 |
Key concepts or prerequisites of transfomer are listed below.
Pre-Training
Complete the task B with a small amount of data through a trained model A (using the shallow parameters of model A)
Let’s take an example to understand pre-training
Eg: Application of pre-training in the field of images
Utilize General characteristics of CNN shallow layer
I trained a model A through 10w data of geese and ducks, 100-layer CNN
Task B: 100 pictures of cats and dogs, classification - CNN on the 100th floor of the training office, impossible to achieve
Try using the first 50 layers of A and 100 layers to complete task B
我们有两个相似的任务A和 B,任务 A已经完成了得到了一个模型A
任务B(数据量小)
用到了一个特性:CNN 浅层参数通用
任务B 就可以使用模型 A的浅层参数,后面的参数通过任务B 训练一》1.冻结(浅层参数不变)2.微调(变) 任务B(大数据)可以训练出模型B(我还可以使用模型 A的浅层参数,节省训练时间,节省成本)
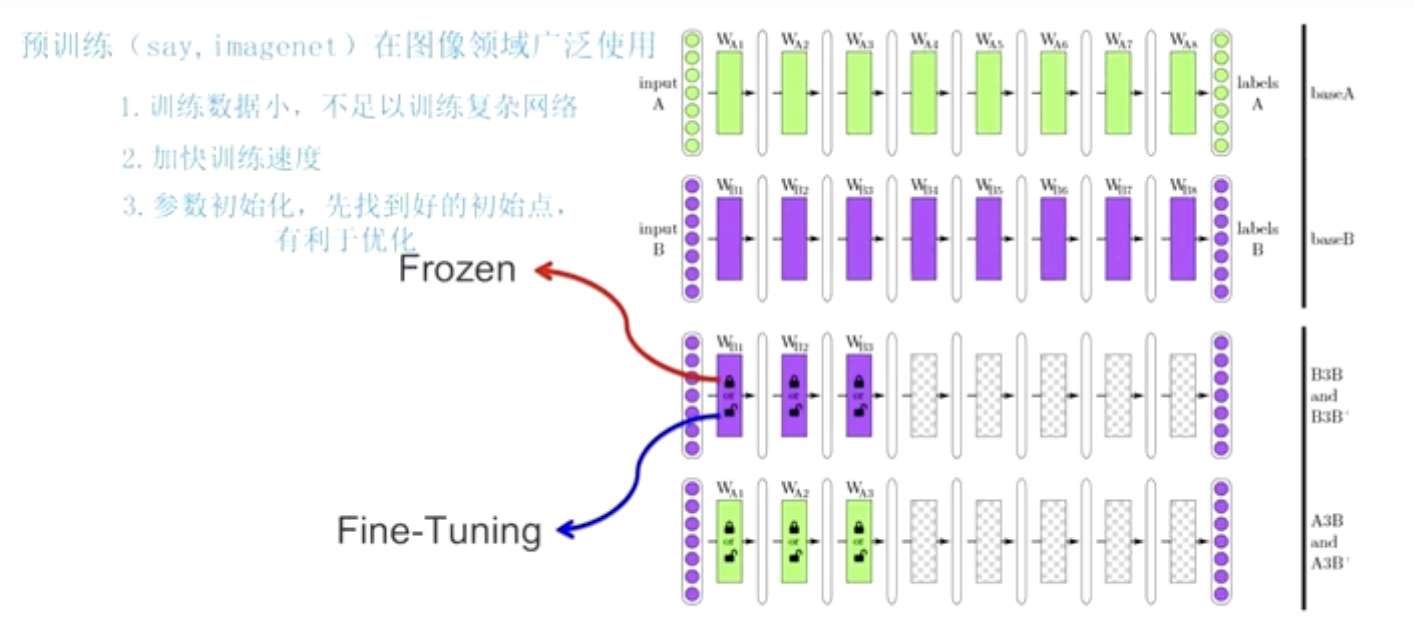
Frozen:The shallow parameters remain unchanged.
Fine-Tuning:Shallow parameters will change as task B is trained
Related technologies
fairseq , transformers Library
Summary
One task A, one task B, the two are very similar.
Task A has trained a model A, using the shallow parameters of model A to train task B, and get model B,
- Fine-tuning (commonly used) .
- Freeze.
Language Model
language(人说的话)+Model(表示某个东西,完成某个任务)
tasks
Comparative Task:Determine which sentence is most likely to appear
P("判断这个词的词性”) P("判断这个词的磁性”)
Prediction Task:predict next word
判断这个词的
___
使用 链式法则 求出 联合概率

P(w_next |“判断”,“这个”,“词”,“的”)
词库(词典)V-》新华字典,高处一个集合,把所有词装到集合V里
把集合里的每一个词,都进行上一步(1)的计算
词库V={“词性”,“火星”}
P(词性|“判断”,“这个”,“词”,”的“)
P(火星|“判断”,“这个”,“词”,“的“)
计算出 哪个词的P最大,就填哪个词
too much cost for the calculation
we only chose n words from the setence to do calculate
it called n-gram language model
n-gram language model
这里其实用到了Markov chain
P(词性|”这个”,“词”,”的”
P(火星|”这个”,“词”,“的“)
P(词性|“词”,“的“)
P(火星|“词”,”的“
P(词性I“的“)
P(火星|“的“)
把n个词,取2个词(3元),取3个词(4 元)
How to calculate the n-gram
1 | “词性是动词“ |
Smoothing strategy
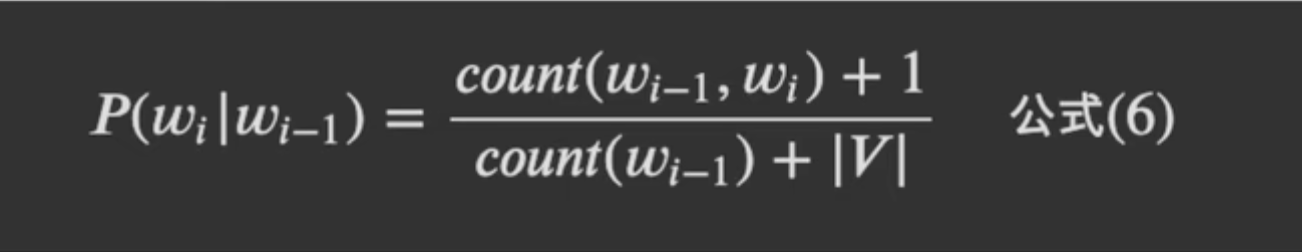
example to understand the formula
We have a very simple document collection
1 | "the cat sat on the mat" |
Vocabulary V will contain the following words:
{the, cat, sat, on, mat, dog, log}
The size of the vocabulary |V| is 7
Using Neural Network to do Predict
one-hot code
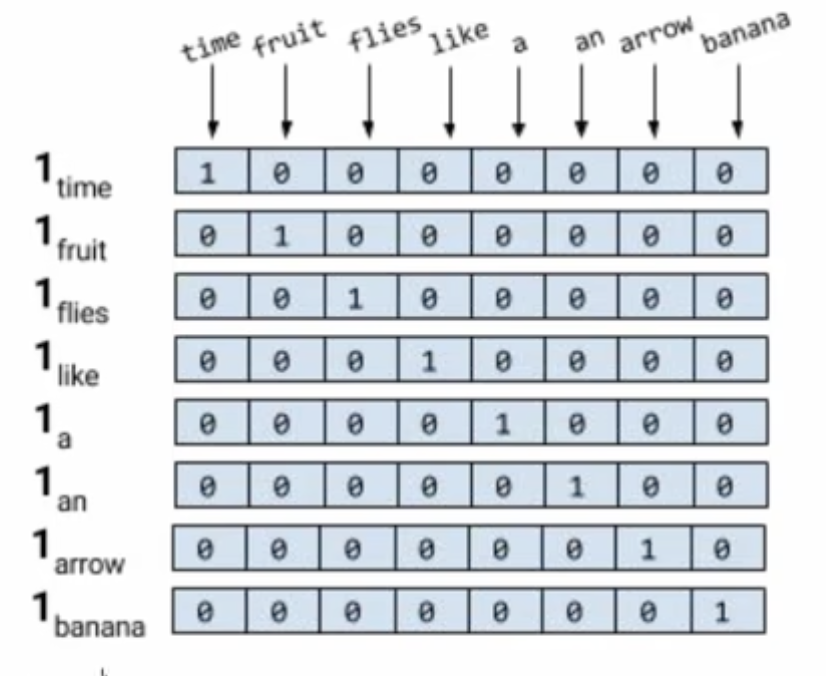
词典V(新华字典里面把所有词集合成一个集合V)
假设词典里面只有8个单词
计算机不认识单词的
但是我们要计算机认识单词
独热编码:给出一个 8*8的矩阵
“time” - 10000000
“fruit” - 01000000
Usinng Cosine similarity calculate the similarity between the two word
in one hot, there is no relationship between each word —> how to improve it
word vector
1 | W1,w2,w3,W4(Unique hot coding of 4 words) |
Eg:
“判断” —> one hot encoding:
w1[1,0,0,0,0]
w1*Q =c1(word vector of “判断” )
the pros of Word vector:
- Control the size of dimensions
- can express the relationship of two words
Word2Vec
the main purpose of word2Vec is to get the word vector
the key of word2Vec is to get Q
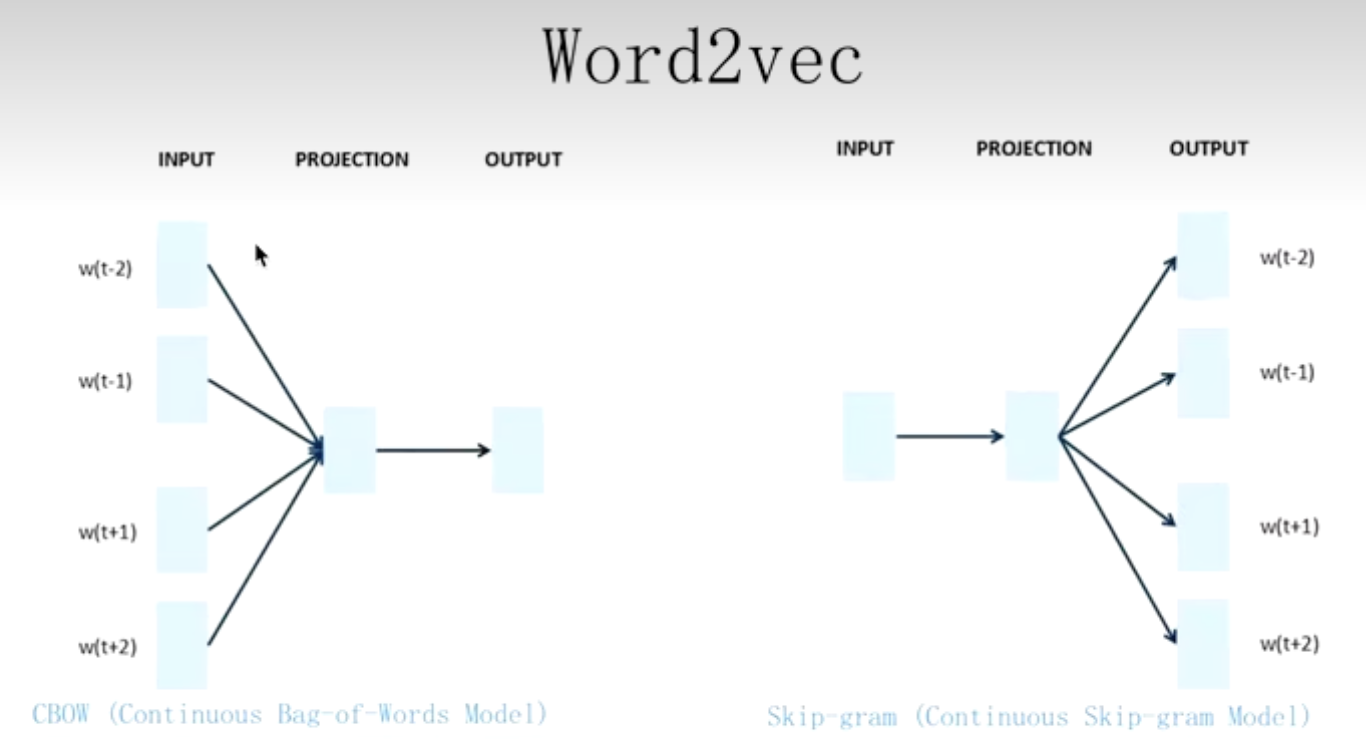
CBOW
Give the context of a word to predict this word.
“我是最_的Nick”
帅
Skip-gram
Give t a word to predict the context of this word.
“帅”
“我是‘_’Nick”
the difference beteween CBOW and Skip-gram
CBOW: 一个老师 告诉 多个学生 Q该怎么变
Skip-gram: 多个老师 告诉一个学生 Q该怎么变
The cons of word2Vec
Unable to solve the problem one word with multiple meanings
Design of Q matrix
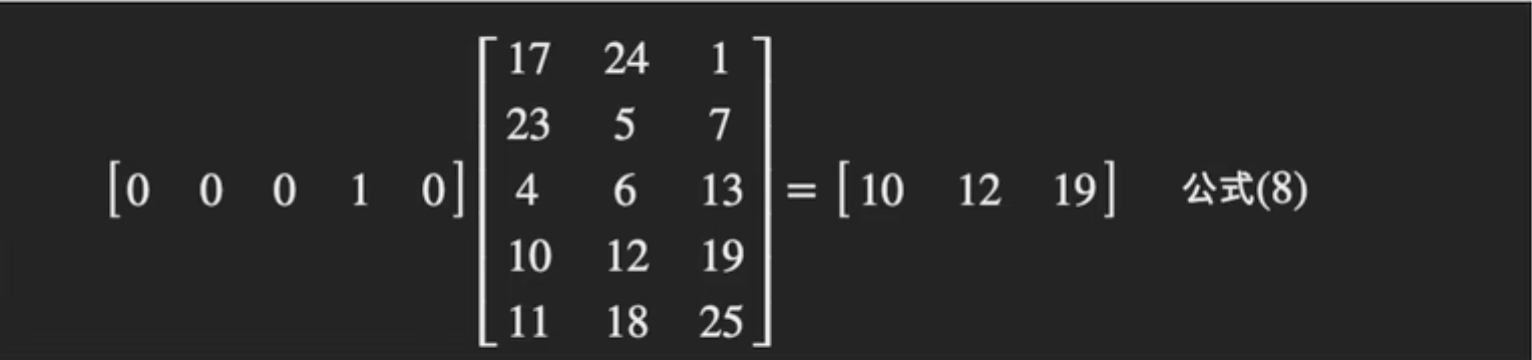
00010 代表 apple x Q= 10, 12, 19
apple(
苹果(水果),苹果(手机))假设数据集里面的apple 只有
苹果(水果)这个意思,没有苹果(手机)这个意思(训练)(测试,应用)10,12,19 apple,无法表示
苹果(手机)这个意思, 因为之前已经训练好了
word2Vec belongs to the pre-training model.
Two tasks A and B are given.
Task A has made model A,
and task B can be solved (by using model A to speed up the solution of the task)
Pre-trained language model(We first use one-hot encoding, then use the Word2Vec pre-trained Q matrix to directly obtain the word vector, and then proceed to the next task)
Freeze: the Q matrix does not need to be changed
Fine-tuning: Change the Q matrix as the task changes
ELMO model
Embeddings Language Models
focus on word vector , same function as the word2Vec
focus on how to slove mutiple meaning of one word
Not only training a Q matrix, but also integrate the contextual information into this Q matrix.
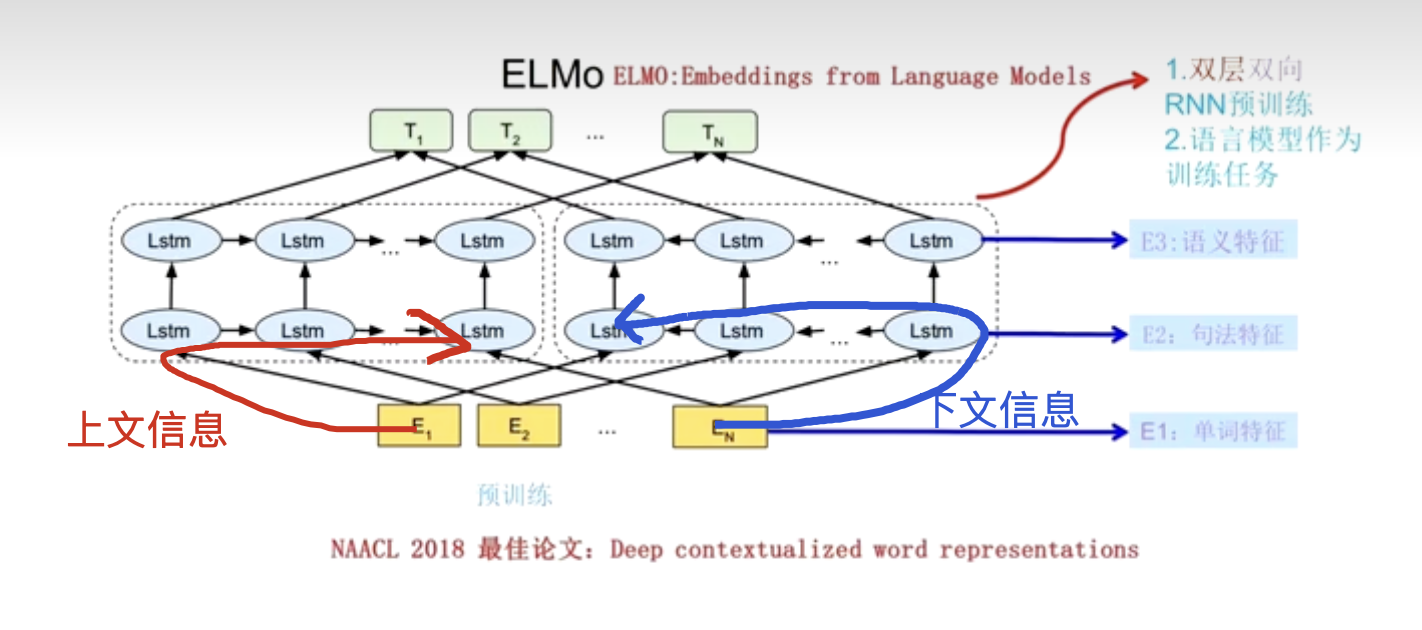
主要看箭头数据流向的方向 左边的是从上文流向下文 右边是从下文流向上文
左边的LSTM 获取 E2 的上文信息,右边就是下文信息
准备来说 是 时间顺序
对比word2Vec 举例子理解
Word2Vec
x1,x2, x4,x5 --> x1+x2+x4+x5
ELMO
After obtaining the context information, the three layers of information are superimposed
E1+E2+E3 = K1 a new word vector = E1
K1 contains the word characteristics, syntactic characteristics and semantic characteristics of the first word.
E2 and E3 are equivalent to two context information.
Essentially, ELMO is a feature extractor that specializes in word vector extraction, very similar to the backbone in computer vision. Just like VGG-16 or something.
eg:
E2, E3 are different, E1+E2+E3 are different
apple -》I ate an apple—》[1,20,10]
apple --》I’m using an apple phone—》[1,10,20]
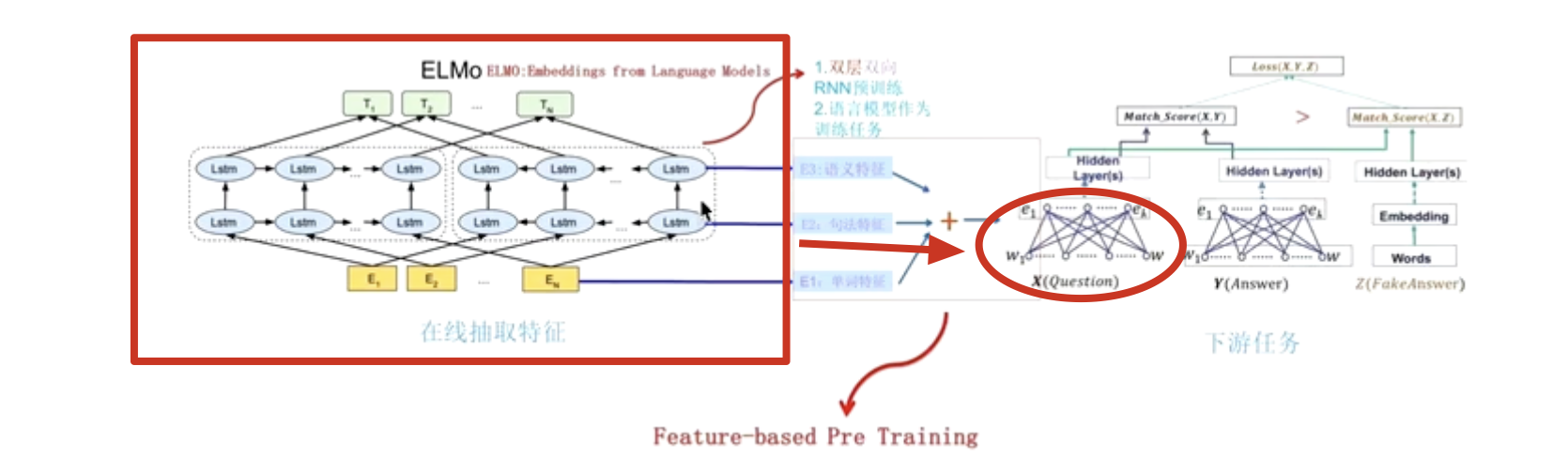
LSTM cannot be parallelized, and long-term dependencies exist and gradients disappear.
Attention
What will you pay attention to?
Big data (all kinds of data, important and unimportant)
For important data, we need to use
For unimportant data, we don’t want to use
For a model (CNN, LSTM), it is difficult to decide what is important and what is not important.
Based on this, the attention mechanism was born.

If you are given this picture, your eyes will focus on the red area.
People — at the face
Article — Look at the title of the article.
Article — Look at the beginning of the paragraph.
How to implement the self-attention mechanism?
for example, I look at one picture.
I (query object Q)
this picture (queried object V)
Looking at this picture, at first glance,
I will judge which things are more important to me and
which are less important to me (to calculate the importance of things in Q and V)
the Importance calculation is the similarity calculation (closer).
Q, K = K1, K2, ••••••, Kn, we generally use the dot product method
By calculating the similarity of each thing in Q and K by point multiplication,
We can get the similarity of Q and a1, the similarity of Q and a2, and the similarity of Q and an.
make a softmax layer
to get the situation with the highest probability
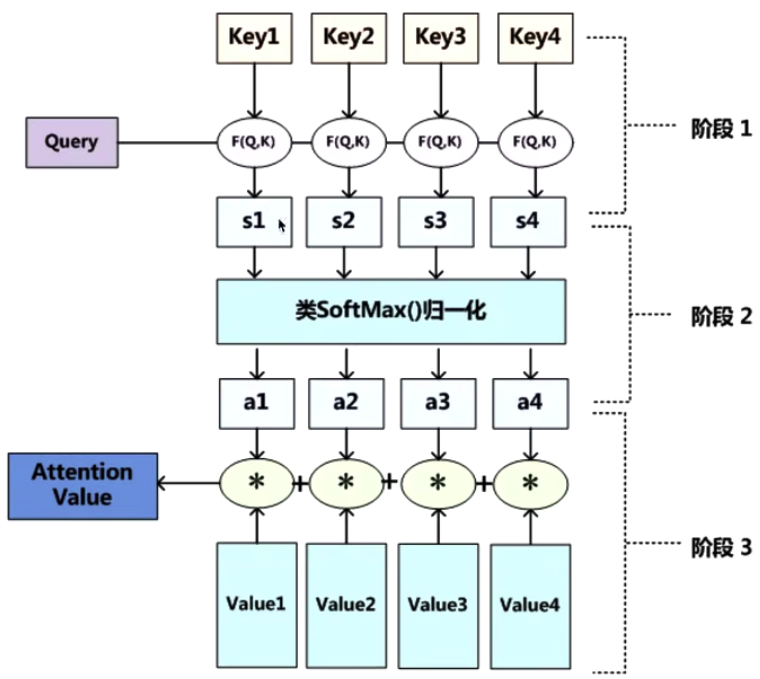
When you use Q to query, Q has lost its use value, and we will eventually get this picture, but the current picture has more information (more important and less unimportant information)
This new V’ contains more important and less unimportant information,
replaces V’ with V.
Attention is putting our attention on more important items.
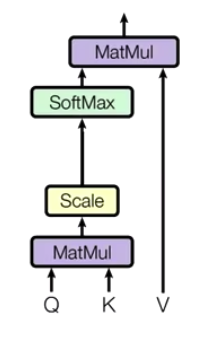
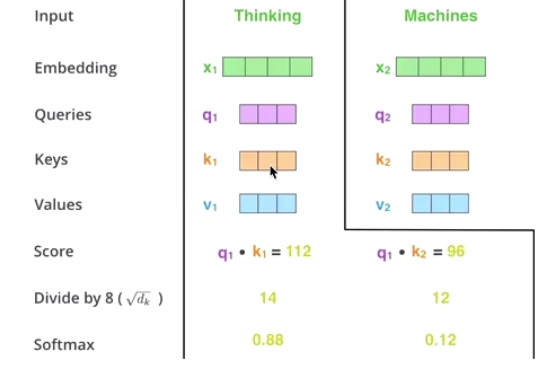
Q * K ----> MatMul
Q times K to get similarity
make a scale based to MatMul —> Scale
sacle is to avoid extreme situations
Scale get softMax to get a probablity
probablity * V ----> MatMul
The new vector represents K and V(K == V)
and this representation also implies the information of Q.
For Q, the most important information in K
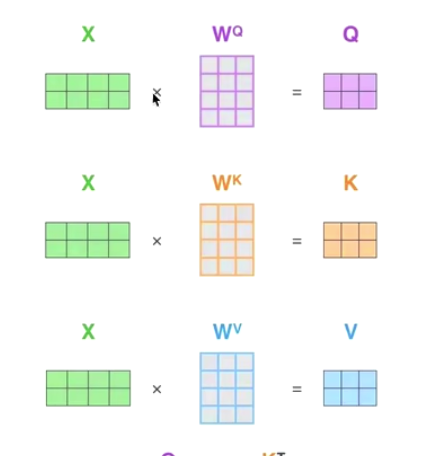
Self-Attention
The key point of self-attention is:
K V Q come from same X
we get Q K V based on X
Just use different linear changes
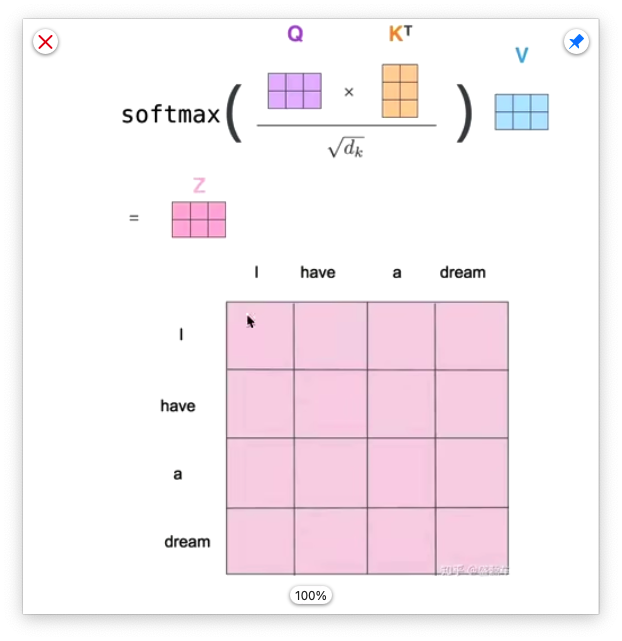
Then use attention mechanism to get the new Vector Z
This new Z will contain correlation degree beteween itself and other words in the sentence
**summary **
- get Q V K
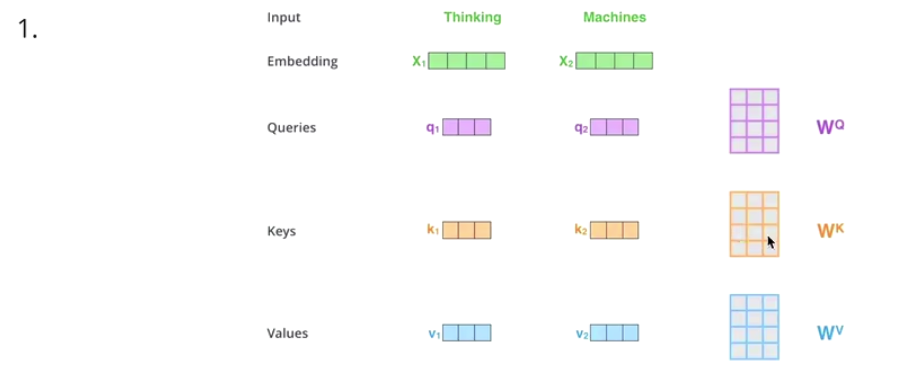
-
Matmul:
get attention score
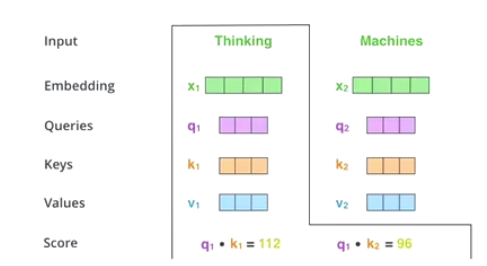
-
scale + softmax
-
matmul:
rerrange the new vector
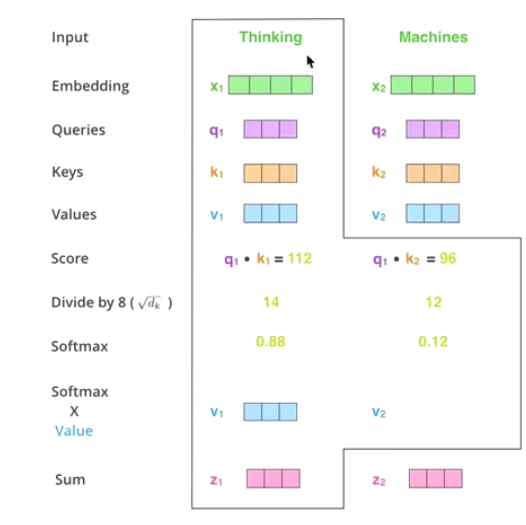
通过 thinking machines
调整 thinking的新向量
对于thinking, 初始词向量为x1
现在我通过 thinking machines 这句话 查询 这句话里面的 每一个单词 和 thinking 之间的 相似度。
新的z1仍然是 thinking词向量的表示,只不过这个词向量 蕴含了 thinking machines这句话的信息。
Take an example to explain the self-attention

Without self-attention,
itsword vector is simply its without any additional information.The new
itsword vector obtained through the self-attention mechanism will contain the information oflawsandapplication.
summary
Attention:
Assuming K==V, then Q is multiplied by K to find similarity A, and then A is multiplied by V to get the attention value Z, which is another form of representation of V.
self-attention:
Q K V comes from the same sources
Cross-attention:
Q and V come from different sources
K and V come from same sources
RNN
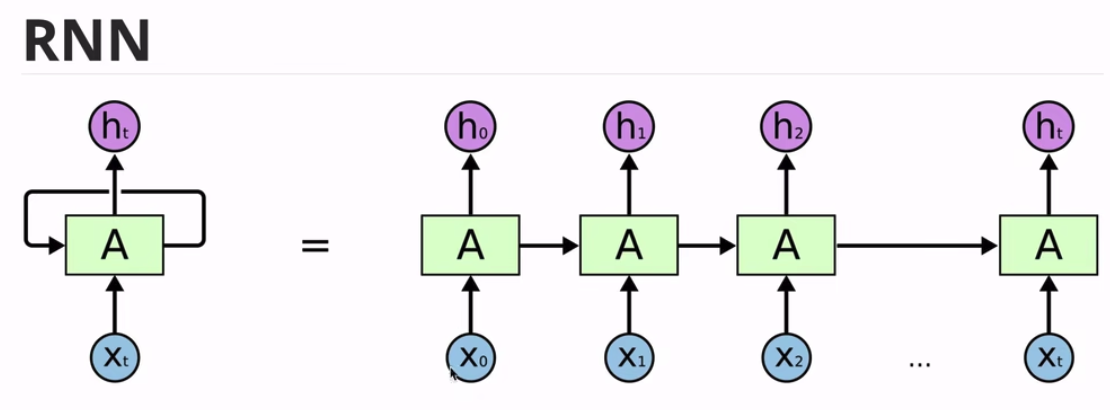
由于链数的增加,导致前期 X0的占比越来越少,
尤其是当Xt比较大,链子比较长,X0的信息基本上就没了。
eg: 50字左右
RNN Shared parameters
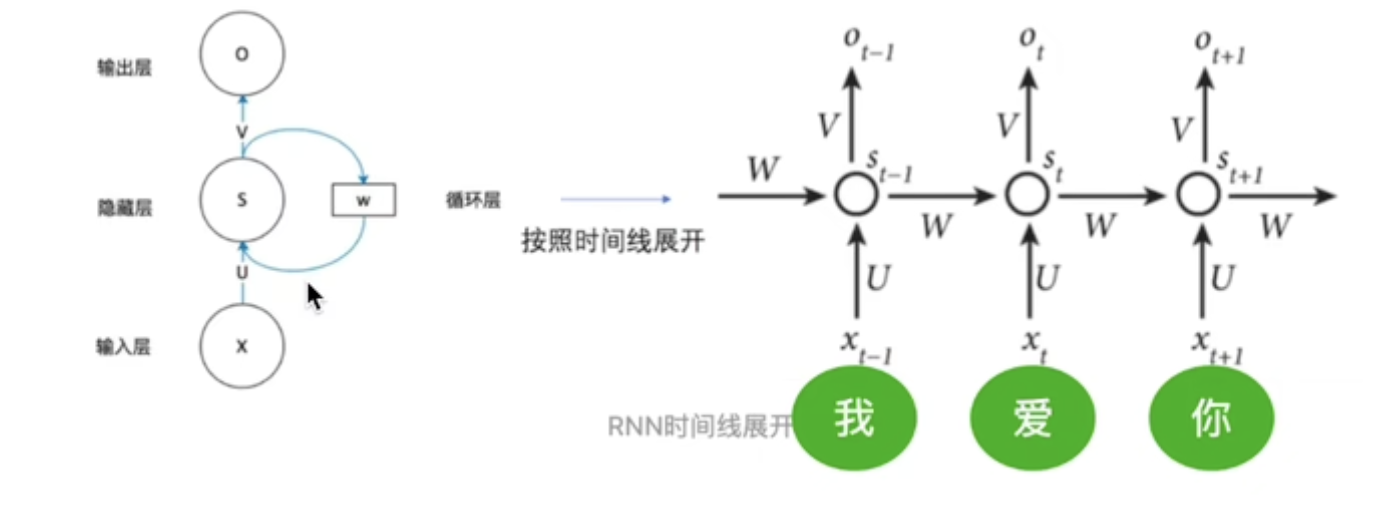
U W V share a set of parameters
Why does RNN have gradient disappear?
The gradient disappearance of RNN is different from other neural networks.
The gradient of RNN is a total gradient
它的梯度消失并不是变为0,而是说 总的梯度 被 近距离的梯度主导,被远距离的梯度忽略不计。
Its gradient disappears not to 0, but the total gradient is dominated by the gradient at a short distance and is ignored by the gradient at a long distance.
Transformers are processed in parallel instead of one by one.
LSTM
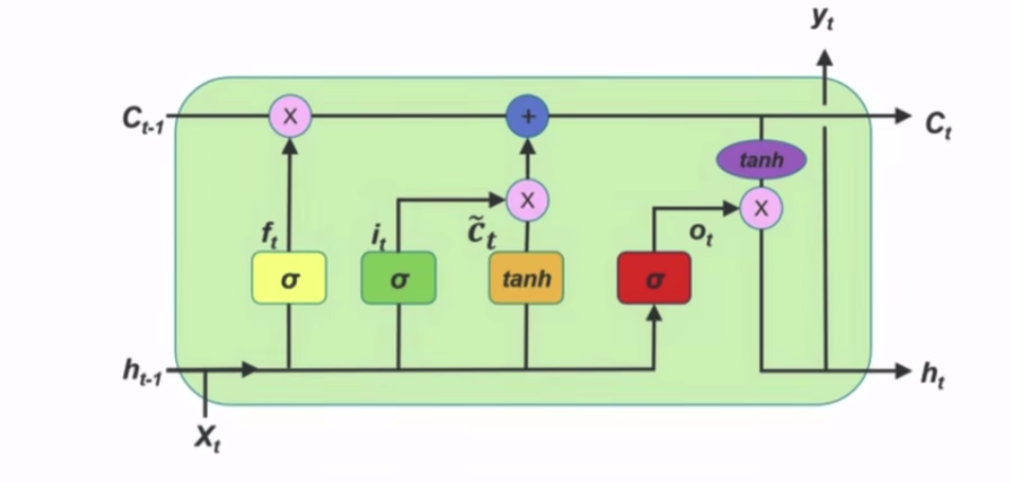
通过增加 遗忘门,等 门,选择性的记忆以前的信息
Eg: 200字左右
Attention 和 RNN 区别
RNNs have long sequence dependency problems and cannot be parallelized.
Mask Attention
你能计算每个单词之间的相似度,这个任务生成文本,一个个单词生成,你没法计算每个单词之间的相似度,因为当生成l时还没有have呢
before mask
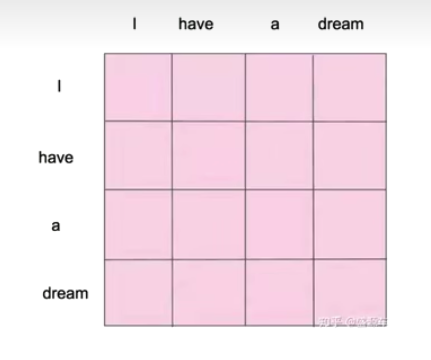
Given an X, get a Z through the self-attention model.
This Z is a new representation of X (word vector).
after mask
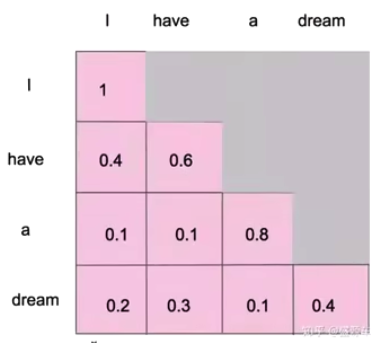
The self-attention mechanism clearly knows how many words there are in this sentence and gives them all at once.
The masks attention is given in batches, and the full amount is given at the last time.
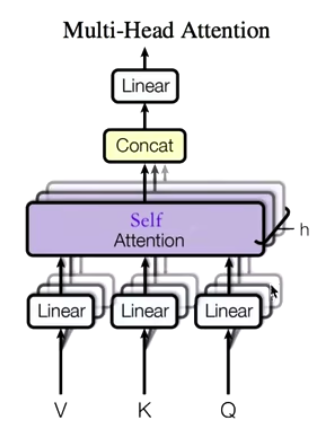
Multi-head Self-Attention
The number of Multi-head is represented by h, generally h=8,
and we usually use the 8-head self-attention mechanism.
The essence of machine learning:
What is the above function doing?
Through non-linear changes, trains the model to make something that seems unreasonable to be reasonable.
What is the nature of nonlinear transformation?
Change the position coordinates on the space, and any point can be found in the dimension space.
Through certain means, an unreasonable point (unreasonable position) can be made reasonable.
one-hot coding (0101010)
word2vec (11, 222, 33)
emlo (15, 3, 2)
attention (124, 2, 32)
multi-head attention (1231,23,3)
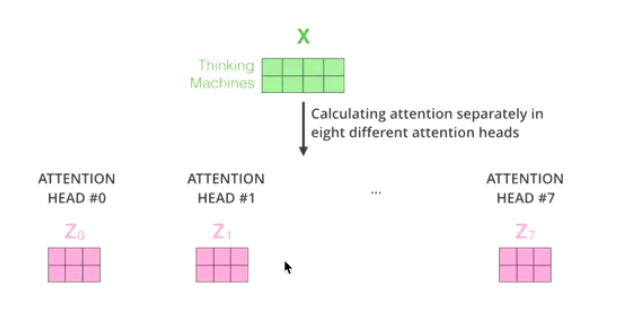
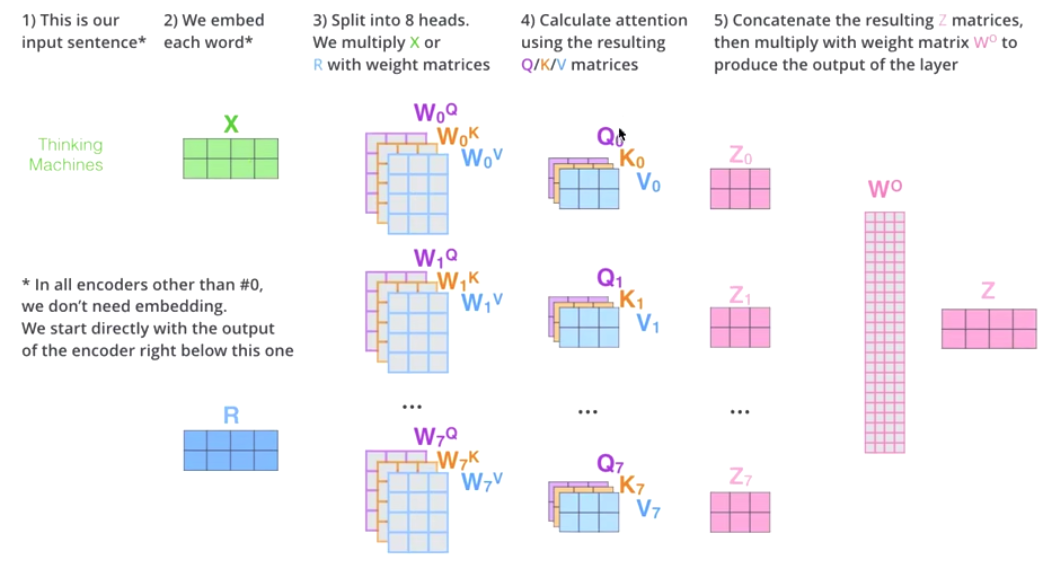
Cuting X into 8 pieces,
In this way, an X that was originally in one position went to 8 positions in space.
By searching for 8 points, a more suitable position was found.
My personal understanding is: Describing the item through the current single feature is not enough to differentiate. Add more different features to describe the thing, thereby increasing the distinction.
The Flow Chart of Multi-head Graph
summary
the pros and cons of attention
Pros:
- solve long sequence dependency problem
- Problems can be solved in parallel
Cons:
- no relationship beteween each word
There is no sequential relationship between words
Position Embedding
i is the index of dimension
d is the dimension
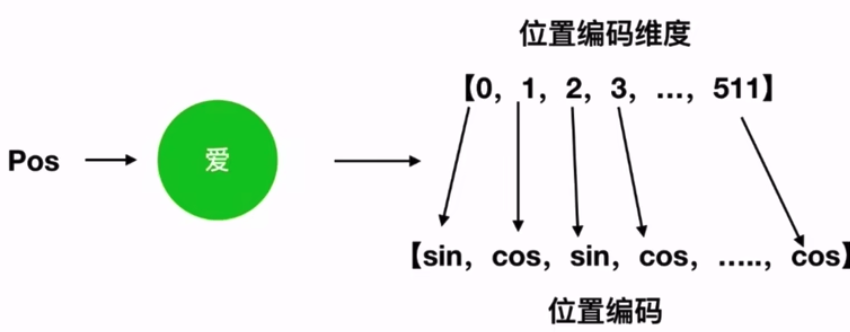
Properties of trigonometric functions
PE(pos + k, 2i) = PE(pos,2i) ✖️ PE(k, 2i + 1) + PE(pos, 2i + 1) ✖️ PE(k, 2i)
PE(pos + k, 2i + 1) =PE(pos,2i + 1) ✖️ PE(k, 2i + 1) - PE(pos, 2i) ✖️ PE(k, 2i)
the even position using sin function
the odd position using cos function
Eg:
pos + k = 5, When we calculate the position code of the fifth word
pos = 1, k = 4, the pos 5 has linear relationship with pos1 and pos4
Pos = 2, k = 3, the pos 5 has linear relationship with pos2 and pos3
1 | sin(postk) = sin(pos)*cos(k) + cos(pos)*sin(k) # sin represents the even dimension. |